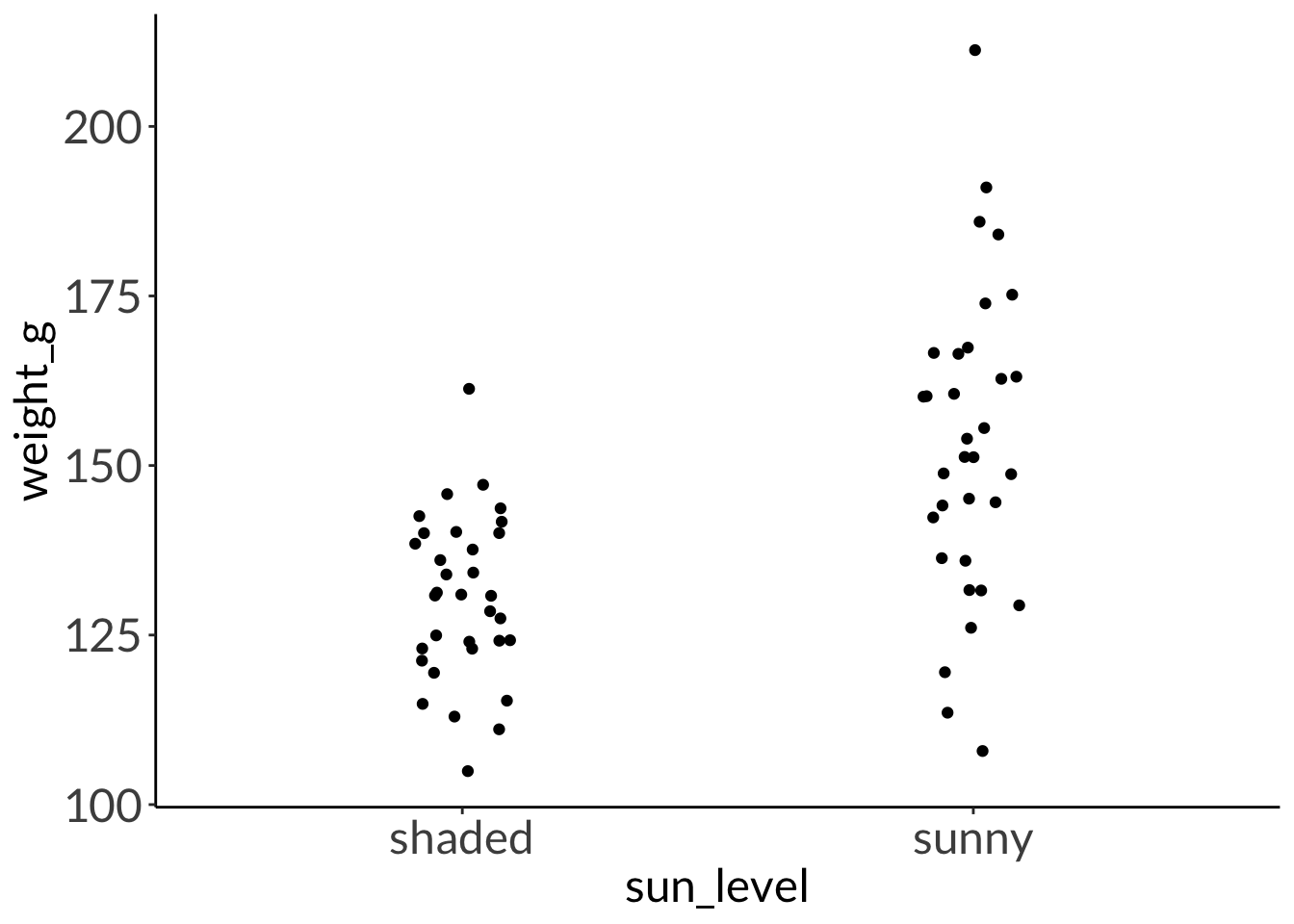
You have two raised beds in which you’re growing tomatoes. One bed is in the sun, but the other is in shade. You want to know if the weight of the tomatoes is different between beds. You measure 33 tomatoes from each bed.
F test to compare two variances
data: weight_g by sun_level
F = 0.2801, num df = 32, denom df = 32, p-value = 0.0005368
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.1383397 0.5671384
sample estimates:
ratio of variances
0.2801031
Welch Two Sample t-test
data: weight_g by sun_level
t = -5.0017, df = 48.622, p-value = 7.811e-06
alternative hypothesis: true difference in means between group shaded and group sunny is not equal to 0
95 percent confidence interval:
-31.45432 -13.42087
sample estimates:
mean in group shaded mean in group sunny
130.4776 152.9152
3. Power analysis
Code
# higher powerpwr.t.test(n =NULL, d =0.7, sig.level =0.05, power =0.95)
Two-sample t test power calculation
n = 54.01938
d = 0.7
sig.level = 0.05
power = 0.95
alternative = two.sided
NOTE: n is number in *each* group
Code
# lower powerpwr.t.test(n =NULL, d =0.7, sig.level =0.05, power =0.80)
Two-sample t test power calculation
n = 33.02457
d = 0.7
sig.level = 0.05
power = 0.8
alternative = two.sided
NOTE: n is number in *each* group
4. Write about this result
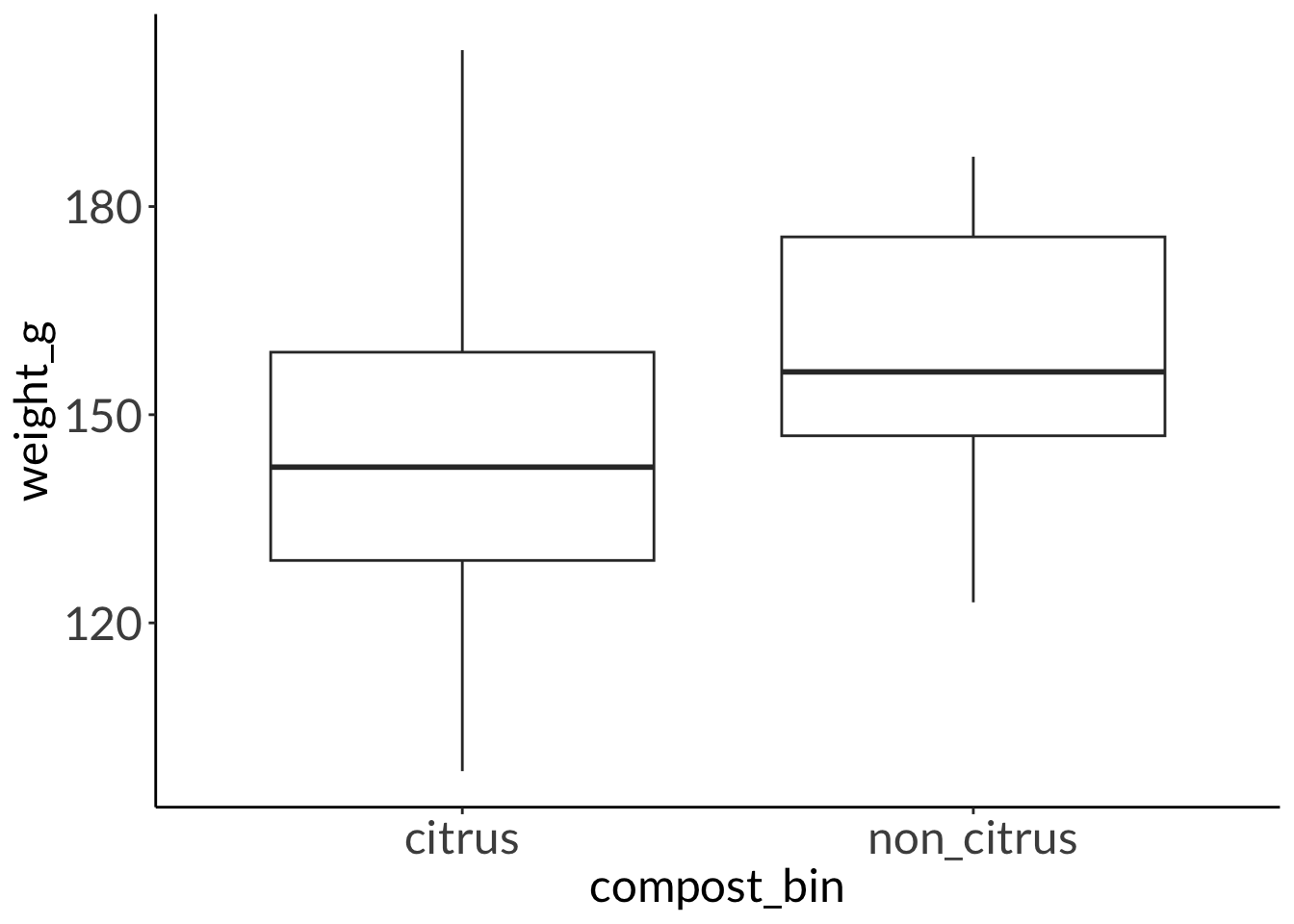
You have two worm compost bins: one in which you throw citrus peels, and the other in which you don’t. You’re curious to see if the citrus worms are bigger than the non-citrus worms. You measure 34 worms from each bin and find this result:
F test to compare two variances
data: weight_g by compost_bin
F = 1.7687, num df = 33, denom df = 33, p-value = 0.1063
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.8833406 3.5415030
sample estimates:
ratio of variances
1.768715
Welch Two Sample t-test
data: weight_g by compost_bin
t = -3.4216, df = 61.276, p-value = 0.001114
alternative hypothesis: true difference in means between group citrus and group non_citrus is not equal to 0
95 percent confidence interval:
-25.035923 -6.567811
sample estimates:
mean in group citrus mean in group non_citrus
144.1785 159.9803
5. Effect size examples
a. large sample size, small difference
Code
set.seed(1)small <-cbind(a =rnorm(n =10, mean =10, sd =2), b =rnorm(n =10, mean =11, sd =2)) %>%as_tibble() %>%pivot_longer(cols =1:2, names_to ="group", values_to ="value")t.test(value ~ group,data = small,var.equal =TRUE)
Two Sample t-test
data: value by group
t = -1.4727, df = 18, p-value = 0.1581
alternative hypothesis: true difference in means between group a and group b is not equal to 0
95 percent confidence interval:
-2.9926364 0.5260676
sample estimates:
mean in group a mean in group b
10.26441 11.49769
Code
set.seed(1)large <-cbind(a =rnorm(n =100, mean =10, sd =2), b =rnorm(n =100, mean =11, sd =2)) %>%as_tibble() %>%pivot_longer(cols =1:2, names_to ="group", values_to ="value")t.test(value ~ group,data = large,var.equal =TRUE)
Two Sample t-test
data: value by group
t = -2.6906, df = 198, p-value = 0.007743
alternative hypothesis: true difference in means between group a and group b is not equal to 0
95 percent confidence interval:
-1.2245098 -0.1887085
sample estimates:
mean in group a mean in group b
10.21777 10.92438
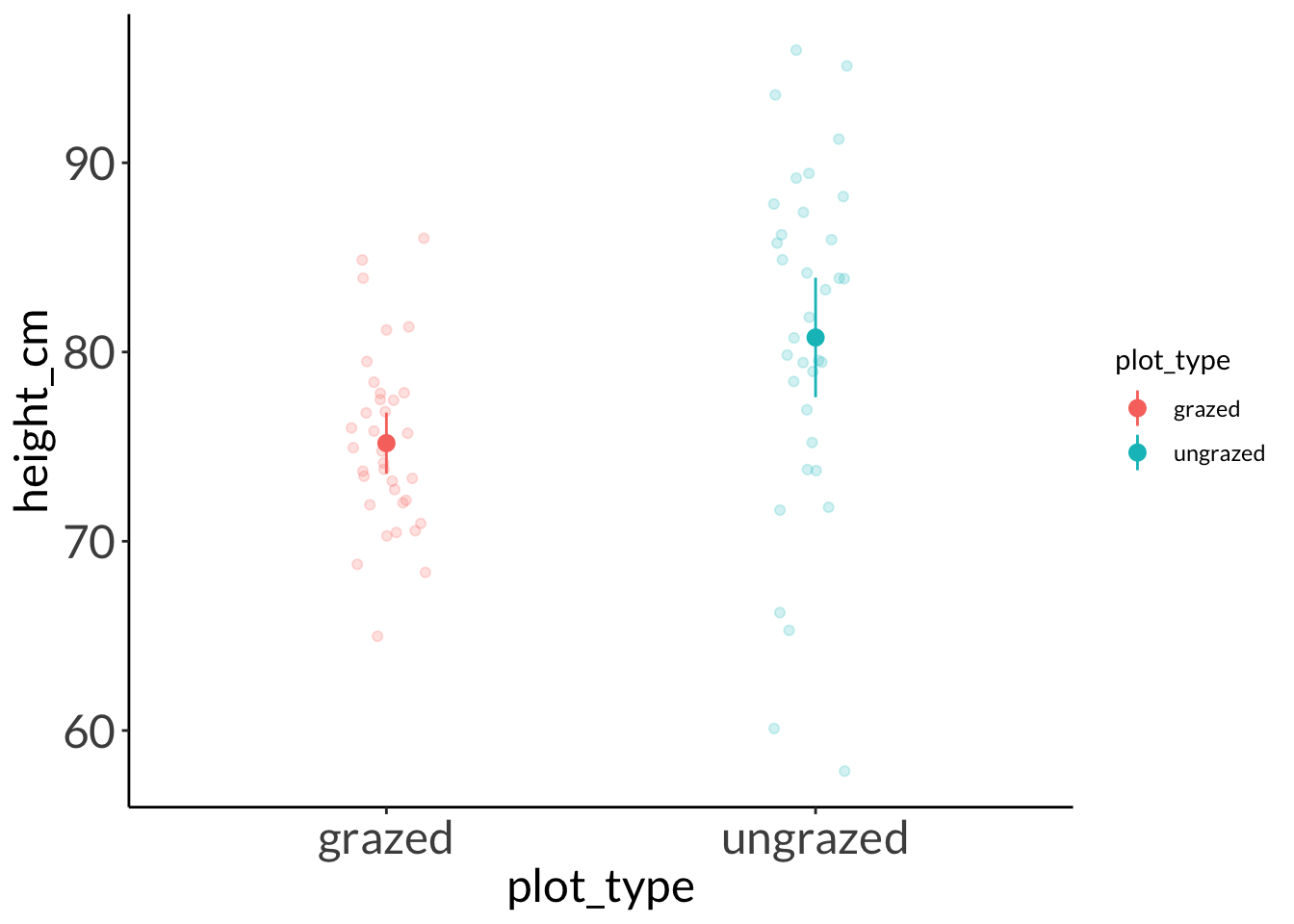
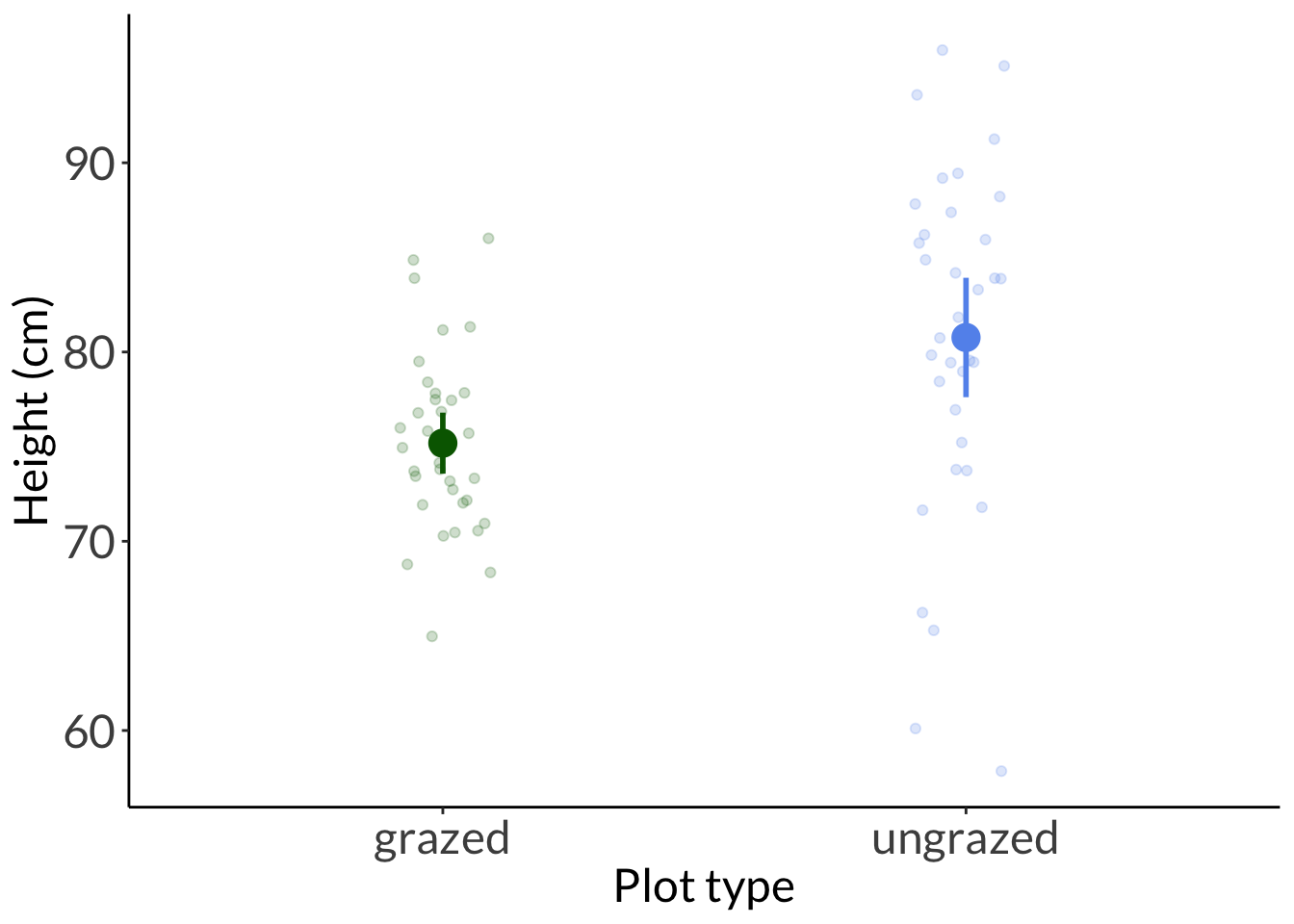
b. needlegrass example
Code
set.seed(1)needlegrass <-cbind(ungrazed =rnorm(n =35, mean =80, sd =10), grazed =rnorm(n =35, mean =74, sd =5)) %>%as_tibble() %>%pivot_longer(cols =1:2, names_to ="plot_type", values_to ="height_cm")# plot without all the adjustmentsggplot(data = needlegrass,aes(x = plot_type,y = height_cm,color = plot_type)) +geom_point(position =position_jitter(width =0.1, height =0, seed =10),alpha =0.2) +stat_summary(geom ="pointrange",fun.data = mean_cl_normal)
F test to compare two variances
data: height_cm by plot_type
F = 0.26151, num df = 34, denom df = 34, p-value = 0.0001765
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.1320008 0.5180813
sample estimates:
ratio of variances
0.2615094
Welch Two Sample t-test
data: height_cm by plot_type
t = -3.2032, df = 50.644, p-value = 0.002351
alternative hypothesis: true difference in means between group grazed and group ungrazed is not equal to 0
95 percent confidence interval:
-9.084836 -2.083807
sample estimates:
mean in group grazed mean in group ungrazed
75.18323 80.76756
Cohen’s d:
Code
# pooled SDcohens_d(height_cm ~ plot_type,data = needlegrass)
Cohen's d | 95% CI
--------------------------
-0.77 | [-1.25, -0.28]
- Estimated using pooled SD.
F test to compare two variances
data: temp by treatment
F = 1.287, num df = 32, denom df = 29, p-value = 0.4953
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.6197933 2.6377877
sample estimates:
ratio of variances
1.286962
Code
t.test(temp ~ treatment,data = pools)
Welch Two Sample t-test
data: temp by treatment
t = -11.206, df = 60.948, p-value < 2.2e-16
alternative hypothesis: true difference in means between group managed and group non-intervention is not equal to 0
95 percent confidence interval:
-2.558536 -1.783706
sample estimates:
mean in group managed mean in group non-intervention
4.952439 7.123560
Code
cohens_d(temp ~ treatment,data = pools)
Cohen's d | 95% CI
--------------------------
-2.81 | [-3.51, -2.10]
- Estimated using pooled SD.
Statement: Our data suggest a difference in water temperature between managed (n = 33) and non-intervention (i.e. control, n = 30) vernal pools, with a strong (Cohen’s d = 2.19) effect of management.
Temperatures in managed pools were different from those in non-intervention pools (two-tailed two-sample t-test, t(60.9) = -8.7, p < 0.001, ⍺ = 0.05); on average, managed pools were 5.3 °C, while control pools were 7.1 °C.
Citation
BibTeX citation:
@online{bui2024,
author = {Bui, An},
title = {Week 4 Figures - {Lectures} 7 and 8},
date = {2024-04-21},
url = {https://spring-2024.envs-193ds.com/lecture/lecture_week-04.html},
langid = {en}
}